
A regular expression, regex is, in theoretical computer science and formal language theory, a sequence of characters that define a search pattern. Usually this pattern is then used by string searching algorithms for "find" or "find and replace" operations on strings4F Source - Wikipedia.
EzeScan uses regexes for various tasks from very simple find to complex find/replace functions.
-
There are books and information available on the internet with regards to Regular Expressions, please refer to them for assistance in creating your required regex.
This section is not aimed at teaching you how to use regexes but to provide a bit of an insight on how regexes may be applied in EzeScan.
EzeScan uses both "Find" and "Find/ Replace" regexes.
-
There are examples of Regex replace examples in the appendices starting on page
Find (Limit) Regex
The Limit Regex option uses a regular expression to match and return specific data from the extracted data.
Find regexes are generally used on the field's "Value tab" (page ) as well as in the Discovery module's "Content Advanced Search" section (page ) and "Skip Content" section (page )
|
Input Text |
This field provides the function of testing what happens when the "find regex" is run.
|
|
Use find regex |
Ticking the box is what will initiate the find regex function.
|
|
Output text |
When a test is run on the regex value the results are shown in the Output text field. The test runs against whatever is typed/imported into the Input text field. |
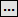
Some Simple Find (Limit) Regex Examples
These are a few examples of a Find (limit) regex which will return a value from a text string based on the regex. Each example contains the regex, some test text and the result.
|
What the regex looks for a 9 digit number in the text string
|
|
||||
|
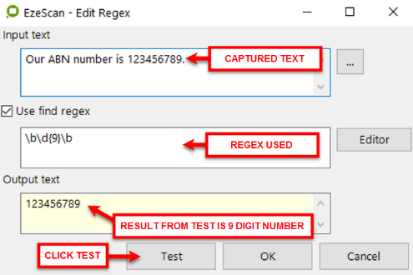
What An example when using the Infor Pathway (property system) integration together with HPE Content Manager (EDRMS). A string is returned from Pathway which contains a value which has the CM container value in it. We need that container value to save the uploaded document into.
(?<=(Pathway Container|Pathway Description)\::)[^|]+
|
_Pathway Link |
Pathway Primary Key::LAP/LAPAPPL/139446 |
Pathway Container:: |
Pathway Description::19-COM, 20 Greenhill Road, WAYVILLE SA 5034
|
|
|---|---|---|---|---|---|
|
What Need to return a value that had {PREFIX} before it and {SUFFIX} after it
|
|
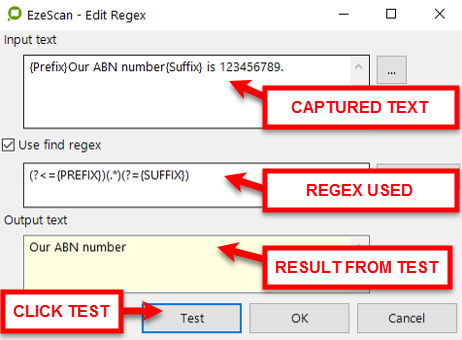
Find / Replace Regex
The difference here is that the regex is expected to find values in a text string and replace it with something else.
This option allows to have multiple text entries to be replaced with other words. i.e. a result could have comau, com;au, com.ai. The Replace With feature can fix all these to show com.au
-
The regex string looks like this -"comau","com.au","com;au","com.au","com,au","com.au","com.ai","com.au"
It is a good way to replace simple things like the letter O with a zero 0 when OCR'ing numbers.
-
1234O66 will become 1234066
-
The regex string looks like this - "O","0"
It can also be very complex by locating a value in a block of text, like used in the EzeScan "Discovery" module to locate an invoice number on a scanned document and replacing it with just the invoice number
-
Invoice 12345 or Inv 12345 or Invoice: 12345 will become 12345
-
The regex string looks like this…
"(?<=^|\s)((inv(oice?)?|doc(ument)?|tax)(\.)? (n(o|br|umber)|#)?|(tax )?invoice) ?[•.,:; ]{0,4} *",""
A sample list of Find / Replace regexes have been provided on page with a larger set of examples included in the appendices on page .
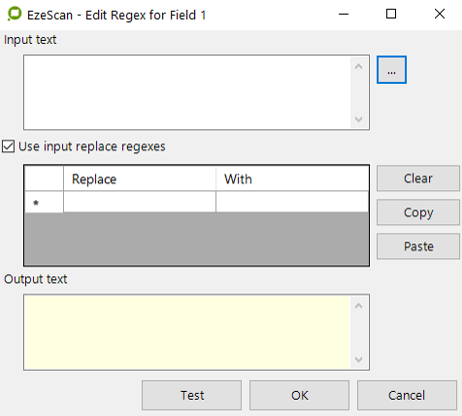
|
Input Text |
This field provides the function of testing what happens when the "find regex" is run.
|
||
|
Use input replace regexes |
Ticking the box is what will initiate the find/replace regex function. |
||
|
Add your regex |
Click in the Replace field to add your regex "find value" and then in the With column to add your regex "replace value". For example:
|
0 |
1 will become PO1234
|
|---|---|---|---|
|
Clear |
Will clear out all regex values in the Replace / With fields |
||
|
Copy |
Will copy the existing regex for use in other KFI field regexes
|
||
|
Paste |
|
||
|
Output text |
When a test is run on the regex value the results are shown in the Output text field. The test runs against whatever is typed/imported into the Input text field.
|
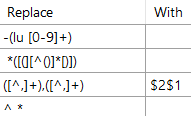
Some Simple Find / Replace Regex examples
|
What Keep a numeric value out of a string
"^[^0-9](\d+)[^0-9]$",
"$1"
|
|
|
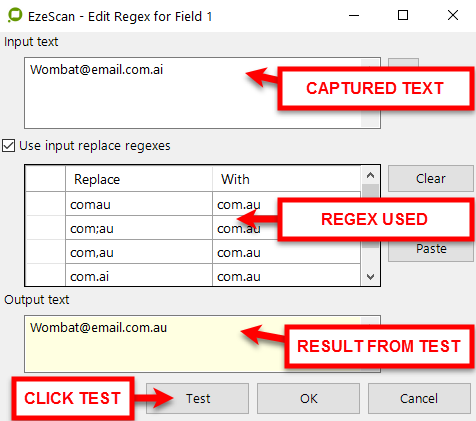
What Multiple text entries to be replaced by one value.In this example an OCR job has returned incorrect values for email addresses.We need com.au
|
|
|
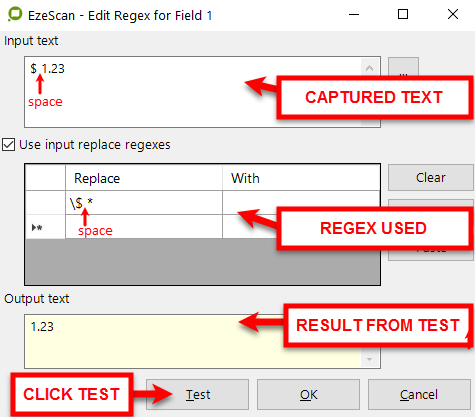
What Remove the $ symbol from a number (with space between $ and number)
|
|
|
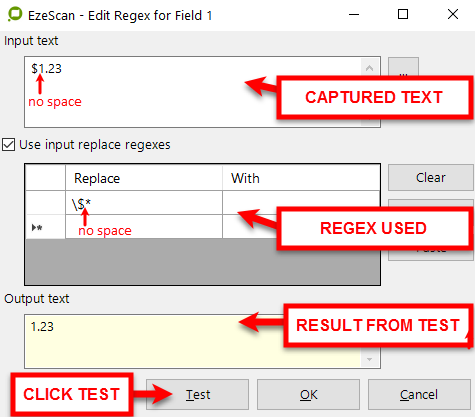
What Remove the $ symbol from a number (with no space between $ and number)
|
|
More Replace Regex Examples
The following Regex codes are rather simple and are commonly used when cleaning up items such as addresses, names etc. There are many websites available which you can visit to learn more about Regex coding and how to apply it to your own EzeScan configurations.
|
What |
Example / outcome |
Paste this |
Blue = Replace value Red = With Value |
||||
|---|---|---|---|---|---|---|---|
|
Keep the last word in a sentence with a forward slash This regex will find the last word in a string which contains a forward slash. If no forward slash then it returns nothing. |
Hello world I am here 1234/789 will become 1234/789; whereas Hello world I am here 1234789 will become nothing (blank) |
".*?([/ ]/[^/ ])?$","$1"
|
|
||||
|
This regex will remove leading 0's and also the first - e.g. from 0001-23456 - Smith, John |
0001-23456 - Smith, John will become 123456 - Smith, John |
"^0*(\d*)-(\d*)( - .*)","$1$2$3" |
|
||||
|
Add "$" as a prefix for if there is a value in the field. If there is no value in the field the field will remain blank |
1 will become $1 |
"^(.+)$","$$$1" |
|
||||
|
Clear out the whole value if it ends with a |12345* will become *NULL 1234\5 will not change |
"^.*+$","NULL" |
|
|||||
|
Keep the first value where it is delimited with two pipes e.g. PO1234 |
0 |
1 |
*PO1234 |
0 |
1* will become PO1234 |
"([|]+).*$","$1"
|
|
|
Remove the first two characters out of a value |
ABCDEF will become CDEF |
"^..","" |
|
||||
|
Clear out the value if there is more than one character |
ABCDEF will become blank Whilst A will remain the same |
"^..+$","" |
|
||||
|
Remove any words that are in brackets |
Smith (MR) will become Smith |
" ([(][^()][)])",""
|
|
||||
|
Replace the third and sixth character with a / |
12112112 will become 12/12/12 |
"^(..).(..).","$1/$2/" |
|
||||
|
Remove multiple commas in a value |
1234,5467,,4444 will become 1234,5467,4444 |
"(\d+)",",$1,","(,\d+,)(?=.*\1)","","^,|,$","",",,+","," |
|
||||
|
Clear the value out if it is not numeric |
ABC will become blankWhilst ABC123 in field will not change |
"^[^0-9]+$",""
|
|
||||
|
Keep the last two words of a value and remove the _ in between them |
one_two_three_four will become three four |
"([]){2}","","_"," "
|
|
||||
|
Search for a word (eg batch) & remove it. Will also remove spaces around the word. |
a big batch of stuff will become a big of stuff |
"\bbatch\b","","\s+"," ","(^\s+|\s+$)","" |
|
||||
|
Remove the first word from a string and then add a second word |
Taxation 2012 will become 2012 FY |
".+ (20[0-9][0-9])","$1 FY"
|
|
||||
|
Remove the second word from a string that is separated by a dash |
Fred - was - here will become Fred - here |
"[^]+",""
|
|
||||
|
Take the last word in a string and put it in the front |
Hello World will become World Hello |
"(.) ([ ])$","$2 $1"
|
|
||||
|
Clear out a value if it does not start with a date value in this format 99/99/99 |
Hello World 25/05/15 will become blankWhilst 25/09/15 will remain the same 25/09/15 |
"([0-9][0-9]/[0-9][0-9]/[0-9][0-9].*)$|().+$","$1"
|
|
||||
|
Keep the second value in a string separated with a dash |
18102594883 - Runners R US Pty Ltd will become Runners R US Pty Ltd |
"([]* - )?([^]+)$","$2"
|
|
||||
|
Remove spaces in a dd/dd/dd type value where there can also be other words in the string (i.e. only removes the space in the date) |
12 /12/12 Hello will become 12/12/12 Hello |
"(\d\d) ?/(\d\d) ?/(\d\d)","$1/$2/$3" |
|
||||
|
Convert a HPE Content Manager KFI browse value to just output the first name and last name |
Flintstone, Fred (Mr) -lu 1660 will become Fred Flintstone |
"-(lu [0-9]+)","",
" ([(][^()][)])","",
"([,]),([,])","$2$1","^ *",""
|
|
||||
|
Convert a HPE Content Manager KFI browse value to just output only the last name |
Flintstone, Fred (Mr) -lu 1660 will become Flintstone |
" -(lu [0-9]+)",""
," ([(][^()][)])",""
,"([,]),([,])","$1","^ * ",""
|
|
||||
|
Convert a HPE Content Manager KFI browse value to just output only the first name |
Flintstone, Fred (Mr) -lu 1660 will become Fred |
" -(lu [0-9]+)",""
," ([(][^()][)])",""
,"([,]),([,])","$2","^ * ",""
|
|
||||
|
Change a numeric value with dashes in a string to remove them. |
Hello World 99-999-999 will become Hello World 99999999 |
"(\d+)-(\d+)-(\d+)","$1$2$3" |
|
||||
|
Add spaces into a numeric value (eg ABN number formatting) |
12345678901 will become 12 345 678 901 |
"(\d{2})(\d{3})(\d{3})(\d{3})","$1 $2 $3 $4" |
|
||||
|
Remove any words after the a particular word (eg service) |
Car Service 15000 KLMS will become Car Service |
"\b(service) .+$","$1" |
|
||||
|
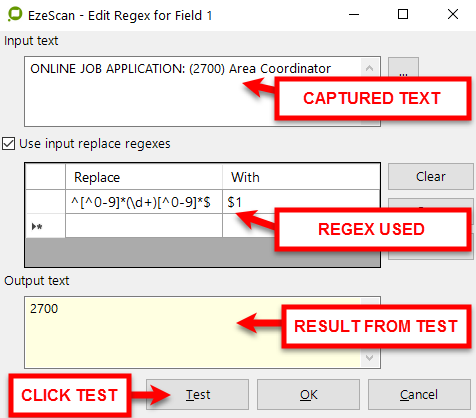
Keep a numeric value out of a string |
ONLINE JOB APPLICATION: (2700) Area Coordinator will become 2700 |
"^[^0-9](\d+)[^0-9]$","$1"
|
|
||||
|
Extract the first numeric value after the word contact |
hello world contact/1234 will become 1234 |
"^.?contact/(\d+).$","$1" |
|
||||
|
Clear out a string if it doesn't contain the value "contact" in it |
hello world contact 1234 will stay as hello world contact 1234 Whilst hello world 1234 will become blank (NULL) |
"^(.contact.)|().+$","$1" |
|
||||
|
Add suffix a .00 if the value does not contain one |
4 and 4.1 will become 4.00 but 4.10 will stay as 4.10 |
^(\d+)$,"$1.00","(\.\d)$","${1}0" |
|
||||
|
Crop the value to only keep the first 20 characters. NOTE - Change the value in {nn} to the required number - includes spaces |
Crop the value to only keep will become Crop the value to on |
"^(.{20}).*","$1" |
|
||||
|
Remove the word VIC and any words after it |
1 Smith Street Melbourne VIC 3100 will become 1 Smith Street Melbourne |
"^(.)\sVIC\s.$","$1" |
|
||||
|
Remove any of the STATES and any words after it |
1 Smith Street Melbourne STATE Postcode etc will become 1 Smith Street Melbourne |
"^(.)\sVIC\s.$","$1","^(.)\sNSW\s.$","$1","^(.)\sQLD\s.$","$1","^(.)\sSA\s.$","$1","^(.)\sTAS\s.$","$1","^(.)\sWA\s.$","$1","^(.)\sNT\s.$","$1" |
|
||||
|
Keep the last five characters from a value NOTE - Change the value in {nn} to the required number - includes spaces |
1 Smith Street Melbourne will become ourne |
"^.*(.{5})$","$1" |
|
||||
|
Remove a carriage return out of a value (adds a space) |
1 Smith StreetMelbourneVIC3106 will become 1 Smith Street Melbourne VIC 3106 |
"[\r\n]+"," "
|
|
||||
|
Remove a dash when there is no second number. For example there is start and end street address fields. |
1 - 10 Smith St will remain the same 1 - 10 Smith St whilst 1 - Smith St will become 1 Smith St |
"(\d+) *- *([a-z]{3})","$1 $2"
|
|
||||
|
Keeps anything to the right of a value that contains a string like "AAA/99/9999 - " |
DA/123/2104 - Test would become Test |
".*- *([-]+)$","$1"
|
|
||||
|
Keep anything after the last dash |
one two three - four will become four |
"^(.*- *)+","" |
|
||||
|
TRIMMING Text - To trim both ends of a string |
spaceBilly Blogsspace would become Billy Blogs |
"^ +| +$","" |
|
||||
|
TRIMMING Text - To trim just the start |
spaceBilly Blogs would become Billy Blogs |
"^ +","" |
|
||||
|
TRIMMING Text - To trim just the end use (don't forget the space at the front of the pattern) |
Billy Blogsspace would become Billy Blogs |
" +$","" |
|
||||
|
Keep the last two words out of a string |
one two three four will become three four |
".* ([ ]+ [^ ]+)","$1"
|
|
||||
|
Add a dot after the first word in a string of words |
one two three will become one.two three |
"([ .]) ([^ ])","$1.$2"
|
|
||||
|
Suffix a 0 on the DD or MM component of a date |
1/1/2015 will become 01/01/2015 |
"/(\d{2})$","/20$1","^(\d)/","0$1/","/(\d)/","/0$1/" |
|
||||
|
This regex will find the last word in a string which contains a forward slash. If no forward slash then it returns nothing |
Hello world I am here 1234/789 will become 1234/789; whereas Hello world I am here 1234789 will become nothing |
".*?([/ ]/[^/ ])?$","$1"
|
|
||||
|
Remove the $ symbol from a number (with space between $ and number) |
$space1.23 will become 1.23 |
"\$ *","" |
|
||||
|
Remove the $ symbol from a number (with no space between $ and number) |
$1.23 will become 1.23 |
"\$*","" |
|
||||
|
Remove the 1st value when separated by a hyphen |
one-two or one - two will become two |
"([]\s)",""
|
|
||||
|
Clear out the value if it does not end in numeric |
Words 123 will remain the sameWhilst Words will become Blank (Nothing) |
"^.*[^0-9]$",""
|
|
||||
|
Remove the last 2 digits and hyphen from a 11 number string |
11-2222-3333-44 will become 11-2222-3333 |
"-d{2}$","" |
|
||||
|
Cleaning up too many hyphens in a word string |
The big - - thing will become The big - thing |
"\b - - - \b," - ","\b - - \b"," - " |
|
Regex quick reference guide
A quick reference guide for some of the popular and most used regex metadata values.
-
This is not an exhaustive list but just one which contains some of the most used matadata values which are incorpoarted in regex scripts. It is strongly recommended to research more about regexes on the internet or speak to your local EzeScan representative for assistance.
Metacharacter
Description
.
Matches any single character except new line (\n). For example…
-
a.c matches "abc", etc.
-
but
[a.c]
matches only "a", ".", or "c".|
***
Matches the preceding element zero or more times. For example…
-
ab*c matches "ac", "abc", "abbbc", etc.
-
[xyz]*
matches "", "x", "y", "z", "zx", "zyx", "xyzzy", and so on
-
(ab)* matches "", "ab", "abab", "ababab", and so on|
^
Is used at the start of a string, or start of line in multi-line pattern. For example…
-
can be used as a replace regex to strip the leading zeros from 000012 to leave 12|
$
Matches the ending position of the string or the position just before a string-ending newline
+
Identifies that there must be one or more of the preceding item
?
Add a ? to a quantifier to make it ungreedy
**
This is an escape character. This is in case you may need to remove a character that is used in regex codes. For example…
-
a forward slash in a date would need to be represented as 01\/01\/2016
-
to remove || at the end of a value you can't do ||$ - you need to do ||$|
( )
Defines a group.
The string matched within the parentheses can be recalled later (see the next entry, \n).
A marked subexpression is also called a block or capturing group\n
Matches what the nth marked subexpression matched, where n is a digit from 1 to 9
<ac:structured-macro ac:name="unmigrated-wiki-markup" ac:schema-version="1" ac:macro-id="e2e3eae3-a2b0-4dfb-815a-99f0def3ed5e"><ac:plain-text-body><![CDATA[
[ ]
A bracket expression. Matches a single character that is contained within the brackets. For example…
]]></ac:plain-text-body></ac:structured-macro>
-
[abc]
matches "a", "b", or "c"
-
[a-z]
specifies a range which matches any lowercase letter from "a" to "z"
-
[A-Z]
specifies a range which matches any uppercase letter from "A" to "Z"
-
These can be mixed:
[abcx-z]
matches "a", "b", "c", "x", "y", or "z", as does
[a-cx-z]
-
<span style="color: #0000ff"><ac:structured-macro ac:name="unmigrated-wiki-markup" ac:schema-version="1" ac:macro-id="5f4f8271-1a11-4b74-a8c2-1dfda5955f7d"><ac:plain-text-body><![CDATA[[0-7]
+matches+ any digit from "0" to "7" \\ \\ The *-* character is treated as a literal character if it is the last or the first (after the ^, if present) character within the brackets:
[abc-]
,
[-abc]
\\ Note that backslash escapes are +not allowed{+}. \\ The \] character can be included in a bracket expression if it is the first (after the ^) character: \[\]abc\]|]]>
<ac:structured-macro ac:name="unmigrated-wiki-markup" ac:schema-version="1" ac:macro-id="30a70412-9ce0-48ce-98e4-99e2ff27e6ec"><ac:plain-text-body><![CDATA[
[^ ]
Matches a single character that is not contained within the brackets. For example…
]]></ac:plain-text-body></ac:structured-macro>
-
[^abc]
matches any character other than "a", "b", or "c"
-
[^a-z]
matches any single character that is not a lowercase letter from "a" to "z"
-
Likewise, literal characters and ranges can be mixed|
\A
Start of string
\Z
End of string
\<
Start of word
\>
End of word
\b
used to identify the start and end of a word (the word boundary). For example…
-
\bcar\b would find the word car in the text string "this is my car"|
\B
Not word boundary
\c
Control character
\s
White space (i.e. spaces between words) For example…
-
^(.)\sVIC\s.$ would remove the "VIC" and any text after it
-
1 Smith Street Melbourne VIC 3100 will become 1 Smith Street Melbourne|
\S
Not white space
\d
Digit
\D
Not digit
\w
Word
\W
Not word